Analyse und Visualisierung von Korpusdaten
Hier stellen wir Werkzeuge und Materialien zu methodischen Aspekten von Korpusuntersuchungen zur Verfügung.
Online-Werkzeug KoGra-R für statistische Auswertungen
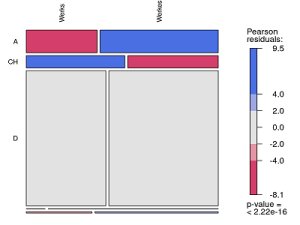 Diese Web-Schnittstelle testet Datenstreuung, Signifikanzen usw. für Korpusauswertungen und visualisiert eine standardisierte Auswahl statistischer Maße.
Diese Web-Schnittstelle testet Datenstreuung, Signifikanzen usw. für Korpusauswertungen und visualisiert eine standardisierte Auswahl statistischer Maße.
Online-Tutorial zur Visualisierung linguistischer Daten
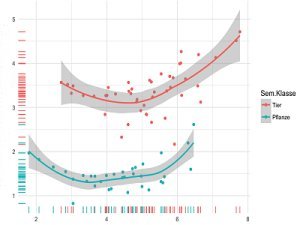 Diese Einführung vermittelt einen anwendungsorientierten Einstieg in die Visualisierung mit R mit praktischen Übungen und linguistischen Anwendungsbeispielen.
Diese Einführung vermittelt einen anwendungsorientierten Einstieg in die Visualisierung mit R mit praktischen Übungen und linguistischen Anwendungsbeispielen.

