Vorhersage von Fugenelementen in nominalen Komposita
(vgl. Bubenhofer/Konopka/Schneider 2014: 183-227)
Diese exemplarische Studie zeigt, wie ein Verfahren des maschinellen Lernens eingesetzt werden kann, um Regeln für die Wahl von Fugenelementen in nominalen Komposita aufzudecken. Auf die Basis eines Trainingskorpus von über 400.000 Komposita wird der Algorithmus C4.5 angewandt, um einen Entscheidungsbaum zu generieren, der die Fugenelemente mit einer hohen Trefferquote vorhersagt. Es wurde versucht, diesen Entscheidungsbaum linguistisch zu deuten, um bestehende Hypothesen über die Wahl von Fugenelementen zu prüfen.
Die Bildung von Fugenelementen in deutschen nominalen Komposita ist ein Forschungsthema mit langer Tradition (z.B. Ortner u. a. 1991; Fuhrhop 1996; Donalies 2011), trotzdem ist es schwierig, konsistente Regeln abzuleiten und die beobachtbare Variation zu erklären. Wichtig ist eine empirische Grundlage, um anhand einer großen Datenmenge Hypothesen über Regularitäten testen zu können. Im Folgenden wollen wir auf der Basis des Deutschen Referenzkorpus des Instituts für Deutsche Sprache (Kupietz u. a. 2010) und damit anhand von etwa 400.000 unterschiedlichen Komposita das Thema statistisch über ein Verfahren des maschinellen Lernens, ein KDD-Verfahren (Knowledge Discovery in Databases), angehen: Es ist das Ziel, durch die Analyse einer Reihe von morphologischen und phonetischen Eigenschaften der Komposita einen Entscheidungsbaum zu modellieren, der Vorhersagen über die Wahl des Fugenelements treffen kann.
Zum einen sollte sich durch die Arbeit mit einem Entscheidungsbaum und durch die ausschließliche Berücksichtigung statistisch signifikanter Daten auf optimale Weise zeigen lassen, welche Kombinationen von Regeln ausschlaggebend für die Gestaltung der Kompositionsfuge sind. Schließlich scheint sich die vermeintliche Fugen-Systematik „nur durch eine Verzahnung der verschiedenen Kriterien“ (Fuhrhop 2000, S. 206), und nicht etwa durch ein Kriterium allein erschließen zu lassen (vgl. Fuhrhop 1996, S. 525).
Zum anderen kann anhand unseres Entscheidungsbaums überprüft werden, ob die Gestaltung der Kompositionsfuge überhaupt an bestimmte Regeln oder Regelverzahnungen gekoppelt ist, oder ob die "Setzung oder Unterlassung" von Fugenelementen als eine "Frage des Sprachgebrauchs, der Konvention [und] der Üblichkeit" (Fleischer 1971, S. 117) zu betrachten ist und somit nicht durch eine Verzahnung von Regeln modellierbar ist. Ramers 1997, S. 44 kommt in diesem Zusammenhang zu dem Schluss, "daß die Wahl des Fugenelements in Komposita keineswegs willkürlich ist, sondern klaren grammatischen Prinzipien folgt". Nicht ohne Grund stellen Wellmann u.a. bereits 1974 für den Wortbildungsprozess der Komposition fest, sie sei "ein besonders aufschlußreiches Prüffeld für die Diskussion der Linguisten, auf welche Weise und inwieweit sich sprachliche Vorgänge adäquat in Regeln fassen lassen" (Wellmann et al. 1964, S. 358).
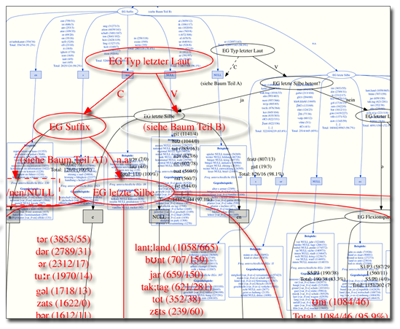
Um die Relevanz von Eigenschaften als Einflussfaktoren für die Fugenbildung einer großen Menge von Komposita berechnen zu können, müssen alle Komposita, die als Datengrundlage dienen, nach diesen Eigenschaften klassifiziert werden. Dies kann nur automatisch geschehen, denn es wäre unmöglich, für über 400.000 Komposita manuell zu bestimmen, welches Suffix, welche Wortart etc. das Erstglied bzw. das Zweitglied aufweisen. Daher können wir auch nur Eigenschaften berücksichtigen, die maschinell bestimmbar sind.
Zur Bestimmung der Eigenschaften verwendeten wir die lexikalische Datenbank CELEX (Baayen u. a. 1995), die eine Reihe von morphologischen, orthographischen und phonologischen Merkmale für die darin enthaltenen Lexeme nennt. Eigenschaften, die in dieser Datenbank nicht genannt werden und so nur schwierig maschinell bestimmbar wären, müssen wir ignorieren, dazu gehören z.B. semantische Merkmale.
Linguistische Erkenntnisse über den Gebrauch von Fugenelementen in Komposita zu gewinnen, ist nur eines der beiden Ziele unseres Ansatzes. Mindestens genau so wichtig ist uns das methodische Experiment: Gelingt es mit maschinellen Lernverfahren, linguistisch sinnvolle Regeln über die Verwendung von Fugenelementen abzuleiten?

