Entscheidungsbaum zur Vorhersage von Fugenelementen
Ein Entscheidungsbaum ist ein gerichteter azyklischer Graph, mit dem Daten automatisch klassifiziert werden können. Er besteht immer aus einem so genannten Wurzelknoten an der Spitze des Entscheidungsbaums, beliebig vielen inneren Knoten (es gibt auch Entscheidungsbäume ohne innere Knoten) und mindestens zwei Blättern. Um einen Fall zu klassifizieren, geht man vom Wurzelknoten abwärts über innere Knoten bis man ein Blatt erreicht. An jeden Knoten wird ein Attribut abgefragt (z.B. „Endet das Erstglied mit einem Konsonanten?“). Je nach Antwort folgt man einem unterschiedlichen Zweig. Das Blatt enthält schließlich die Klassifikation (z.B. „Fugenelement ist ‚s’“). Vgl. zu Illustration die folgende Abbildung:
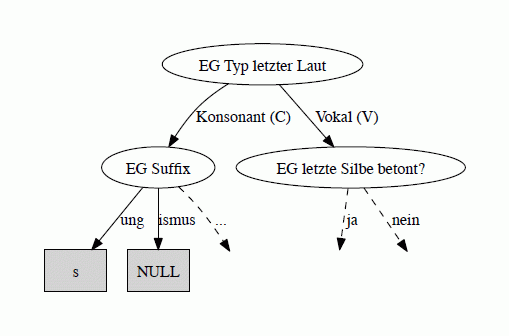
Abbildung 1: Ausschnitt aus einem Entscheidungsbaum zur Vorhersage von Fugenelementen (EG = Erstglied)
Entscheidungsbäume können mit maschinellen Lernverfahren auf der Basis von Trainingsdaten automatisch erstellt werden. Wir haben im Folgenden den von Quinlan (1993) entwickelten Algorithmus C4.5 verwendet, der in der Software-Suite WEKA (Witten/Frank 2005) als J48 in Java implementiert ist. Bei der Konstruktion des Entscheidungsbaums geht der Algorithmus folgendermaßen vor: Ziel ist, in den Blättern des Entscheidungsbaums nur noch Fälle einer Klasse (z.B. „Fugenelement ist ‚s’“) vorzufinden. Dazu werden zunächst alle Fälle des Trainingsdatensatzes betrachtet. Jedes Attribut wird daraufhin getestet, ob es die Datenmenge in möglichst ‚reine’ Gruppen aufteilt was das Zielattribut betrifft. Das Maß, das der C4.5-Algorithmus zur Bewertung der Attribute verwendet, heißt Kullback-Leibler-Divergenz (Kullback/Leibler 1951). Das Attribut mit dem höchsten Wert wird ausgewählt und der Trainingsdatensatz in Teilmengen nach diesem Attribut aufgeteilt. Für jede Teilmenge werden wiederum die übrigen Attribute anhand der Kullback-Leibler-Divergenz bewertet und nach der Auswahl des Attributs mit dem höchsten Wert in weitere Teilmengen aufgeteilt. Dieser Prozess wiederholt sich, bis eine Teilmenge nur noch Fälle einer Klasse enthält oder die vom Benutzer vorgegebene minimale Anzahl von Fällen pro Blatt erreicht ist. Das Blatt erhält dann die Klasse mit den meisten Fällen. Da die Gefahr besteht, dass der so trainierte Entscheidungsbaum zwar die Trainingsdaten optimal klassifiziert, unbekannte Daten jedoch nicht gut klassifiziert (Gefahr der Überanpassung an die Trainingsdaten), wird der Entscheidungsbaum in einem letzten Schritt noch ‚zurückgeschnitten’ (‚pruning’).
Für die Fugenelementanalyse haben wir mehrere Bäume trainiert, im Folgenden werden jedoch nur die Resultate des einen Baums dargestellt. Die Trainingsdaten dieses Baums enthalten jede Erstglied-Zweitglied-Folge nur ein einziges Mal, egal wie häufig sie in den Korpora vorkommt (vgl. dazu auch das Kapitel "Datenaufbereitung"). Wenn eine Erstglied-Zweitglied-Folge in den Korpora mit verschiedenen Fugenelementen vorkommt (so gibt es z.B. sowohl Abfahrtszeit als auch Abfahrtzeit), so wird als Zielattribut ein variables Fugenelement angegeben (in diesem Fall ‚[var_s_0]’).

