Recherche- und Analysemethoden, methodisch relevante Datenbereiche
In der Genitivdatenbank konnten einerseits die Belege bzw. die Datensätze einzeln betrachtet und qualitativ untersucht werden.
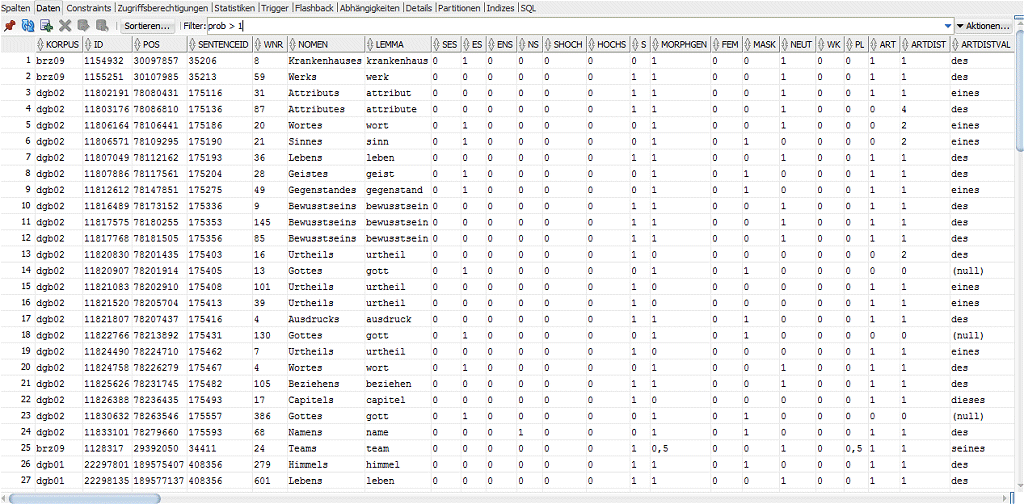
Abbildung: Die ersten Spalten der Genitivdatenbank
Andererseits konnten darin mithilfe von SQL-Befehlen (vgl. nachstehendes Listing) für die Untersuchung relevante Untergruppen der Genitivnomen isoliert und quantitativ ausgewertet werden.
select letztlauttyp, count(*) from korpusschema.tb_genitiv6 where prob > 1 and es = 1 and propn = 0 and abk = 0 and neo = 0 and fremdw = 0 and konversionen = 0 and HK > 7 and celex = 'j' and anzsilb = 1 group by letztlauttypListing: SQL-Kommando, mit dem sich pro Auslauttyp (Konsonant, Vokal) die Anzahl von Genitivtoken ermitteln lässt, die auf -es enden und nicht den Sonderwortschatzbereichen zugerechnet wurden sowie deren Grundformen – im DEREWO – die Häufigkeitsklasse > 7 haben und in CELEX vollständig und als Einsilber aufgeführt sind.
Da nicht zu allen Genitivtoken alle Arten von Metaangaben vorlagen, rückten im Laufe der Untersuchung verschiedene Teile der Datenbasis in den Vordergrund, z. B.:
- alle Nomen mit Prob > 1,
- alle Nomen mit Prob > 1 ohne Sondergruppen,
- alle Nomen mit Prob > 1 ohne Sondergruppen, deren Lemma bzw. Lemmazweitglied in CELEX erfasst ist,
- alle Nomen mit Prob > 1 ohne Sondergruppen, deren Lemma vollständig in CELEX erfasst ist.
In den jeweils relevanten Gruppen der Genitivnomen fanden die quantitativen Analysen zu mutmaßlichen Variationsfaktoren in der Regel sowohl aus der allgemeinen Tokensicht als auch aus lemmabezogener Sicht statt, die sich der lexembestimmten Perspektive annäherte. Bei diesen Analysen wurde sowohl auf deskriptiv- als auch inferenzstatistische Verfahren zurückgegriffen wie:
- Berechnungen relativer Häufigkeiten,
- Berechnungen zur Effektstärke (Phi-Koeffizient, (logarithmierte) Odds Ratio),
- binäre logistische Regression.
Als Korrektiv bei Verallgemeinerungen der Ergebnisse von Datenbankanalysen wurden immer wieder „klassische“ Recherchen in COSMAS II herangezogen. Sie wurden darüber hinaus wichtig, wenn für die Beschreibung einiger spezifischer Nomenbereiche die Genitivdatenbank als Datenquelle offensichtlich unzureichend wurde (vgl. Endungslose Genitive).
Trotz aller Vorkehrungen, die getroffen wurden, um eine optimale Datenbasis bereitzustellen und die Ergebnisse abzusichern, darf hier wie bei allen solchen Untersuchungen nicht vergessen werden, dass primär die zur Verfügung stehende Datenbasis beschrieben wird und die Standardsprache nur in einer Annäherung in Augenschein genommen werden kann.

