Obligatorische Endungslosigkeit bei Personennamen und Fremdwörtern
Zur Beantwortung der ersten Frage haben wir die folgenden Merkmalskombinationen abgefragt: (i) Fremdwort auf -us; (ii) Fremdwort auf s-Laut (<s, x, z>); (iii) Eigenname auf s-Laut (<s, x, z>); (iv) fremdsprachlicher Eigenname auf s-Laut (<s, x, z>). Die Ergebnisse sind in der folgenden Tabelle wiedergegeben. Für eine bessere Einschätzung der Befunde haben wir in der untersten Zeile die Verteilung der Endungsvarianten bei regulären Appellativen aufgeführt, die keine der Eigenschaften aufweisen, die das Auftreten einer Nullendung begünstigen und daher eigentlich obligatorisch eine overte Genitivmarkierung verlangen.1 Bei den dabei auftretenden 1,7% Nullendungen handelt es sich daher i.d.R. um Fehler (entweder Schreibfehler oder Fehler bei der Annotation/Extraktion). Diesen Vergleichswert werden wir auch in der Folge verwenden, um zu überprüfen, ob ein bestimmter Faktor die Wahl der Nullendung günstig beeinflusst.
1 In unserer Genitivdatenbank können diese Nomen durch die folgenden Eigenschaften identifiziert werden: PropN = 0, PropNManuell = 0, Titel = 0, Zeitausdruck = 0, Abk = 0, Neo = 0, Fremdwort = 0, Konversion = 0, Kompositum = 0. Ein Verzeichnis der relevanten Faktoren/Abkürzungen findet sich hier.
| Nullendung | Apostroph | overte Markierung | Token Insgesamt | |
| Fremdwort auf -us | 48.412 (98,8%) | 0 | 570 (1,2%) | 48.982 |
| Fremdwort auf s-Laut (<s, x, z> exkl. -us) | 15.319 (97,3%) | 10 (<0,1%) | 415 (2,6%) | 15.744 |
| Eigenname auf s-Laut | 62.241 (73,4%) | 9.361 (11%) | 13.197 (15,6%) | 84.799 |
| Eigenname+Fremdw. auf s-Laut (<s, x, z>) | 314 (80,5%) | 10 (2,6%) | 66 (16,9%) | 390 |
| reg. Appellative | 52938 (1,7%) | 34 (0,001%) | 3.031.047 (98,3%) | 3.084.018 |
Tabelle 1: Konsistenter Wegfall der Genitivendung bei EN und Fremdwörtern auf -s
Insgesamt sind die in Tabelle 1 gezeigten Unterschiede zwischen Fremdwörtern und Eigennamen auf der einen Seite und regulären Appellativen auf der anderen Seite sehr eindeutig. Dies lässt sich auch durch inferenzstatistische Analysen bestätigen. Dem Chi-Quadrat-Test zufolge weicht die beobachtete Verteilung höchst signifikant (p = 0,0004998) von einer Gleichverteilung ab. Allerdings ist dieser Befund bei der hohen Zahl an Belegen nicht sehr überraschend.2 Etwas aussagekräftiger ist die Berechnung der standardisierten Pearson Residuals. Dabei wird geschätzt, inwieweit die beobachteten Häufigkeiten von den erwarteten Häufigkeiten in einzelnen Zellen abweichen. Ist der Betrag des entsprechenden Residuums größer als 1,96, ist von einer signifikanten Abweichung von der erwarteten Häufigkeit auszugehen. Die folgende Tabelle 2 zeigt, dass dies durchgängig für die Faktoren in Tabelle 1 zutrifft. Eine entsprechende Visualisierung der Ergebnisse über einen Assoziationsplot findet sich in Abbildung 1. Das Vorzeichen des jeweiligen Residuums zeigt eine Abweichung von der Erwartung nach oben bzw. unten an.
| Nullendung | Apostroph | overte Markierung | |
| Fremdwort auf -us | 877,08 | -11,94 | -212,11 |
| Fremdwort auf s-Laut (<s, x, z> exkl. -us | 489,07 | -5,29 | -118,35 |
| Eigenname auf s-Laut | 839,37 | 580,06 | -235,88 |
| Eigenname+Fremdw. auf s-Laut (<s, x, z>) | 62,89 | 8,32 | -15,72 |
| reg. Appellative | -285,37 | -94,4 | 74,48 |
Tabelle 2: Konsistenter Wegfall der Genitivendung bei EN und Fremdwörtern auf -s (standardisierte Pearson Residuals)
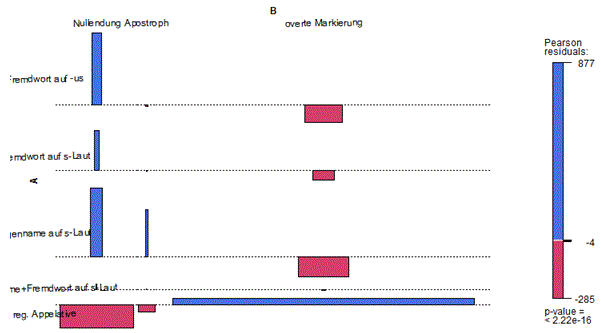
Abbildung 1: Assoziationsplot: Konsistenter Wegfall der Genitivendung bei EN und Fremdwörtern auf -s
Die Grafik visualisiert die Befunde in Tabelle 2, d.h. die standardisierten Abweichungen der beobachteten Häufigkeiten von den unter einer bestimmten Unabhängigkeitshypothese erwarteten Häufigkeiten. Jede Zelle wird durch ein Rechteck repräsentiert, dessen Höhe proportional zum Residuum der Zelle und dessen Breite proportional zur Wurzel der erwarteten Häufigkeit ist. Die Fläche des Rechtecks ist daher proportional zur Differenz von beobachteten und erwarteten Häufigkeiten. Generell gilt, dass kräftige Farben eine hochsignifikante Abweichung signalisieren, während (schwach) signifikante Abweichungen durch Pastellfarben markiert werden; nicht-signifikante Abweichungen entsprechen grau eingefärbten Flächen (in Abbildung 1 sind alle Abweichungen hochsignifikant).
Wie in Abbildung 1 gezeigt, geht bei den untersuchten Fremdwörtern und Eigennamen eine starke Präferenz für die Nullendung (signalisiert durch blau eingefärbte Flächen) mit einer Abweichung zu Ungunsten einer overten Markierung des Genitivs einher (rot eingefärbte Flächen). Bei den regulären Appellativen verhält es sich (wie erwartet) genau umgekehrt. Zu den Ergebnissen im Einzelnen: Die Zahlenverhältnisse für Fremdwörter auf s-Laut sind besonders klar: Rund 98% aller Belege weisen eine Nullrealisierung des Genitivs auf. Bei den wenigen Ausnahmen handelt es sich primär um stark integrierte Fremdwörter wie Omnibus, Bonus, Zirkus oder Index (die den Plural z.T. auf -e bilden), von denen in der Literatur oft angenommen wird, dass sie sich z.T. eher wie native Wörter verhalten. Allerdings zeigen unsere Korpusbefunde, dass hier offenbar ein großes Maß an Variation vorliegt (vgl. Omnibus: 35x -es vs. 9x Null; Bonus: 103x Null3; Index: 85x -es vs. 319x Null, Rhinozeros: ausschließlich Nullendungen (13x)). Wir können also feststellen, dass Hypothese (1), Invariante Fälle für (nicht integrierte) Fremdwörter auf -us bzw. Sibilant durch die Ergebnisse unserer Korpusrecherche bestätigt wird.
3 In unserer Genitivdatenbank treten ausschließlich endungslose Formen für Bonus auf. Eine COSMAS-Recherche (W-gesamt, DeReKo 2013-I, 06.11.2013) bringt es aber immerhin auf 25 Belege für Bonusses.
Etwas schwieriger zu interpretieren ist der Befund für Eigennamen auf -s. Dies liegt vor allem daran, dass wir auf der Basis der vorliegenden Annotation nicht zwischen Personennamen und anderen (geografischen) Namen unterscheiden können;4 obligatorische Endungslosigkeit erwarten wir aber nur bei Personennamen auf -s (bei geografischen Namen wie des Nördlinger Rieses ist eine Verwendung der langen Genitivendung /-es/ durchaus möglich). Ein etwas klareres Bild ergibt sich, wenn wir Eigennamen auf s-Laut betrachten, denen ein Nomen nachfolgt. In der überwiegenden Zahl der Fälle haben wir es hier mit vorangestellten Personennamen in der Funktion eines Genitivattributs (Fritz’ Tasche) zu tun (i.d.R. können in dieser pränominalen Position nur Personennamen, aber keine geografischen Namen auftreten: *des Rieses Fauna):
4 Eine entsprechende semiautomatische Annotation (z.B. auf das Basis entsprechender Wörterlisten mit anschließender manueller Korrektur der Ergebnisse) wäre mit einem erheblichen Aufwand verbunden gewesen und konnte daher im Rahmen der vorliegenden Studie nicht geleistet werden. Eine bei niederfrequenten Phänomenen mangelnde Trennschärfe stellt ein allerdings ein generelles Problem von Ansätzen dar, die auf die Verarbeitung großer Datenmengen mittels automatisch ablaufender Suchroutinen ausgerichtet sind.
| Nullendung | Apostroph | -ens | sonstige Markierungen | Token insgesamt | |
| Eigenname auf s-Laut vor Nomen | 7.760 (54,2%) | 5.106 (35,7%) | 615 (4,3%) | 825 (5,8%) | 14.306 |
Tabelle 3: Konsistenter Wegfall der Genitivendung: EN auf s-Laut + Nomen
Tatsächlich findet sich hier in 4,3% der Fälle noch die Endung -ens (z.B. Leibnizens Bemühungen). Außerdem können wir beobachten, dass der Anteil der Nullendungen zugunsten der Fälle mit Apostroph abnimmt, die in diesem Kontext besonders häufig auftreten. Ein Problem scheint jedoch im Zusammenhang mit der Beobachtung aufzutreten, dass es 825 Fälle gibt, in denen eine andere Endung (außer -ens) erscheint. Wenn man diese Fälle einer näheren Betrachtung unterzieht, kann man allerdings feststellen, dass hier vor allem fehlerhafte Daten vorliegen. So wird beim Name der Ratingagentur Moody’s das finale <s> sowohl als Stammauslaut als auch als Genitivmarkierung per Apostroph-s gewertet (allein 503 von 825 Fällen). Bei den verbleibenden 322 Fällen scheint es sich primär um englische Namen mit Apostroph-s zu handeln (z.B. St. James’s (50x), Dr. Seuss’s ABC (16x)). Wir können also festhalten, dass ca. 90% der Eigennamen auf -s ohne eine morphologische Markierung des Genitivs auftreten. Der Wert scheint jedoch unter den entsprechenden Werten für Fremdwörter auf -us bzw. <s, x, z> zu liegen. Dies wirft die Frage auf, ob Hypothese (1), Invariante Fälle tatsächlich in der vorliegenden Form aufrechterhalten werden kann. Entscheidend ist hierbei der Status der Endung -ens: Wenn man dieses Element als produktives Flexiv der Gegenwartssprache einschätzt, dann muss Hypothese (1), Invariante Fälle entsprechend modifiziert werden. Lässt sich hingegen zeigen, dass dieses Flexiv vor allem in älteren Texten auftritt, dann könnte Hypothese (1), Invariante Fälle – mit Einschränkung auf die Gegenwartssprache – weiterhin Geltung beanspruchen. Eine entsprechende statistische Untersuchung, die den Einfluss des Erstellungsjahrs eines Textes auf die Häufigkeit der -ens Endung überprüft, hat jedoch ergeben, dass die Effektstärke des Faktors Zeit/Erstellungsjahr äußerst gering ausfällt (Cramér’s Phi < 0,1). Mit anderen Worten, wir müssen die Geltung von (1), Invariante Fälle dahingehend einschränken, dass bei Personennamen auf s-Auslaut zwar endungslose Varianten (inkl. Apostroph) stark dominieren (> 90%), die Markierung mittels -ens aber dennoch auch im Gegenwartsdeutschen weiterhin eine marginale Option darstellt (4,3%). Ferner wäre zu überprüfen, ob die Endung -ens bevorzugt in bestimmten Textsorten/Registern auftritt. Bei positiver Beantwortung dieser Fragestellung könnte dann (1), Invariante Fälle unter der Einschränkung beibehalten werden, dass es sich bei der Endung -ens um eine stilistisch markierte Variante handelt, die nur in bestimmten hochsprachlichen Kontexten auftritt.
Die Betrachtung von Nomen, die eine Kombination der Merkmale Eigenname, Fremdwort und Stammauslaut auf s-Laut aufweisen (vorletzte Zeile von Tabelle 1), scheint ebenfalls zu einem Problem zu führen. Nach dem, was wir bisher gesehen haben, würden wir erwarten, dass eine Häufung von Eigenschaften, die eine Nullendung begünstigen, den Effekt verstärken sollte. Tatsächlich scheint aber im vorliegenden Fall der Befund alles andere als eindeutig zu sein. Zwar überwiegen die Formen ohne sichtbare Genitivmarkierung deutlich (314x, 80,5%); der Anteil der Nullendungen ist aber nur geringfügig größer als bei den Eigennamen auf s-Laut (73,4%). Noch überraschender ist der deutliche Rückgang der Bildungen mit Apostroph (2,6% vs. 11%, allesamt Zacharias’) sowie die Beobachtung, dass der Anteil der Formen mit overter Endung sogar noch angestiegen ist (16,9% vs. 15,6%, freilich in erster Linie auf Kosten der Fälle mit Apostroph). Völlig unerwartet fällt schließlich der Vergleich mit Fremdwörtern auf s-Laut aus, die einen wesentlich höheren Anteil an endungslosen Varianten aufweisen (97,3%). Eine nähere Überprüfung dieses Ergebnisses hat jedoch gezeigt, dass die 66 Fälle, die hier als overt markierte Genitive ausgezeichnet sind, tatsächlich falsch annotiert sind: 31x Pluss (Eigennamen wie z.B. Etienne Pluss, wobei fälschlich ein Lemma Plus zugrunde gelegt wird), 17x Albatross (offensichtlicher Schreibfehler bzw. englische Schreibweise bei Zitaten), 7x (Grand) Prixs (ausschließlich Pluralformen), 4x Minuss (Schreibfehler), 2x Omnibuss (Akronym für das Projekt Online-Monitoring natürlicher, inhalativallergener Bioaerosole und sonstiger Staubkomponenten, fälschlicherweise dem Lemma Omnibus zugeordnet), 1x Quizs (Plural), 1x Pessimismuss (nicht normgerechte Schreibung), 1x Coxs (falsch geschriebener Städtename Cox’s Bazar), 1x Diskuss (fälschlich dem Lemma Diskus zugeordnete Abkürzung von Diskussion), sowie 1x Luftikus Terminuss (Name einer Vorarlberger Gauklertruppe, fälschlich dem Nomen Terminus zugeordnet). Wenn man diese 66 Fälle abzieht, ergibt sich folgendes Ergebnis (die vorletzte, bereinigte Zeile ist grau schattiert):
| Nullendung | Apostroph | overte Markierung | Token insgesamt | |
| Fremdwort auf -us | 48.412 (98,8%) | 0 | 570 (1,2%) | 48.982 |
| Fremdwort auf s-Laut (<s, x, z> exkl. -us) | 15.319 (97,3%) | 10 (<0,1%) | 415 (2,6%) | 15.744 |
| Eigenname auf s-Laut | 62.241 (73,4%) | 9.361 (11%) | 13.197 (15,6%) | 84.799 |
| EN+Fremdw. auf s-Laut (<s, x, z>) | 314 (96,9%) | 10 (3,1) | 0 | 324 |
| reg. Appellative | 52938 (1,7%) | 34 (0,001%) | 3.031.047 (98,3%) | 3.084.018 |
Tabelle 4: Konsistenter Wegfall der Genitivendung bei EN und Fremdwörtern auf -s, bereinigt.
Es zeigt sich nun das erwartete Bild: Die Kombination der Faktoren "Eigenname", "Fremdwort" und "Endung auf s-Laut" führt im Vergleich zu der Faktorenkombination "Eigenname+s-Auslaut" zu einem deutlichen Anstieg der Nullendungen. Die Tatsache, dass in diesem Zusammenhang nur wenige Fälle mit Apostroph auftreten, ist auf die geringe Zahl entsprechender (bzw. entsprechend zugeordneter) Namen im Korpus zurückzuführen (wie bereits erwähnt, tritt ausschließlich der Personenname Zacharias’ auf). Auch dieses Ergebnis ist hochsignifikant (Chi-Quadrat Test: p < 0,0005; standardisierte Pearson Residuals noch eindeutiger als in Tabelle 2).
Wir können also abschließend feststellen, dass unsere Korpusstudie Hypothese (1), Invariante Fälle zumindest partiell bestätigt. Bei Fremdwörtern hat sich gezeigt, dass der letztlich schwer zu bemessende Faktor Integration, der die hauptsächliche Quelle grammatischer Variation in diesem Bereich ist, eine entscheidende Rolle spielt. Es hat sich in diesem Zusammenhang auch angedeutet, dass der Grad der Integration eines Fremdworts nicht unmittelbar auf die Häufigkeit/Geläufigkeit im Korpus zurückgeführt werden kann: Bei Omnibus überwiegen die Formen auf -ses (79,5%), das Wort kommt aber insgesamt nur 44x im Korpus vor. Im Gegensatz dazu haben wir es mit 404 Fällen von Index zu tun, von denen allerdings lediglich 85 (21%) mit Endung (-es) auftreten. Für den Grad der Integration sind also offenbar noch andere Faktoren wie z.B. Nähe zum Grundwortschatz relevant. So reflektiert die relative Häufigkeit des Wortes Index wohl weniger seine allgemeine Geläufigkeit als vielmehr die Tatsache, dass es in einer bestimmten, im Korpus prominenten Textsorte (Zeitungsnachrichten) besonders gängig ist. Dennoch haben sich im Rahmen unserer Korpusstudie auch Hinweise darauf ergeben, dass zumindest bei geografischen Namen starke Veränderungen der Token-Häufigkeit auch die Distribution der Genitivvarianten beeinflussen (vgl. Nübling 2012; s.u. für die entsprechenden Befunde).

