Interaktion von Faktoren
Unsere Untersuchungen haben gezeigt, dass ein Übergewicht endungsloser Varianten in der Regel das Resultat eines Zusammentreffens mehrerer Faktoren ist, die Endungslosigkeit begünstigen.1 In diesem Abschnitt möchten wir entsprechende kumulative Effekte im Zusammenhang mit der Genitivmarkierung von Eigennamen (sowie die dabei auftretenden Probleme) näher betrachten.2
1 Wie bereits ausführlich diskutiert, stellen Abkürzungen eine Ausnahme dar (vgl. Obligatorische Endungslosigkeit bei Abkürzungen und Konversionen), da sie unabhängig vom Auslaut eine sehr starke Neigung zur Endungslosigkeit aufweisen.
2 Eine Aufarbeitung der folgenden Befunde mithilfe fortgeschrittener statistischer Methoden (Effektstärkenschätzung, Regressionsanalysen etc.) steht bislang noch aus.
Eigennamen auf Sibilant
Wir haben bereits festgestellt, dass Eigennamen, die auf Sibilant enden, den Genitiv überwiegend endungslos realisieren. Allerdings wäre hier eine feinkörnigere Unterscheidung zwischen Personennamen und geografischen Namen wünschenswert, da bekannt ist, dass letztere weniger stark zur Endungslosigkeit neigen. Auf der Basis der in unserer Datenbank enthaltenen Informationen können wir evtl. einen Teil der Personennamen dadurch ausschließen, dass wir die Fälle, in denen unmittelbar ein weiteres Nomen folgt, nicht berücksichtigen, da Personennamen als Genitivattribut bevorzugt dem Kopfnomen vorangehen (vgl. Tabelle 3 im Abschnitt Obligatorische Endungslosigkeit bei Personennamen und Fremdwörtern). Es ergeben sich die folgenden Zahlen:
| Nullendung | Apostroph | overte Markierung | Token insgesamt | |
| Eigenname auf s-Laut insgesamt | 62.241 (73,4%) | 9.361 (11%) | 13.197 (15,6%) | 84.799 |
| Eigenname auf s-Laut ohne nachfolgendes Nomen | 54.481 (77,3%) | 4.255 (6,1%) | 11.757 (16,6%) | 70.493 |
Tabelle 1: Häufigkeit der Nullendung bei Eigennamen auf s-Laut
Wie aus Tabelle 1 hervorgeht, erscheinen über 70% der Eigennamen auf s-Laut im Korpus ohne Genitivendung. Wenn man dabei ausschließlich Fälle ohne nachfolgendes Nomen betrachtet (negativer Wert für das Kriterium "NNPost"), so verändert dies vor allem den Anteil der Nullendungen auf Kosten der Fälle mit Apostroph, das vor allem bei Personennamen als Auslassungssignal Verwendung findet. Allerdings haben wir es hier immer noch mit über 4000 Belegen zu tun. Dies ist z.T. auf eine fehlerhafte Erkennung des Genitivs (z.B. Namensbestandteile wie d’ oder l’) zurückzuführen. Bei der überwiegenden Zahl der Apostroph-Fälle handelt es sich aber um Personennamen auf s-Laut, denen eine Kombination von Adjektiv und Nomen nachfolgt (z.B. Hingis’ gute Laune), die nicht als (komplexes) nachfolgendes Nomen erkannt wird. Dies zeigt, dass ein positiver Wert für das Kriterium "NNPost" zwar für die Identifikation von Personennamen herangezogen werden kann (vgl. Tabelle 3, Obligatorische Endungslosigkeit bei Personennamen und Fremdwörtern); umgekehrt ist es aber nicht ohne Weiteres möglich, über einen negativen Wert Namen herauszufiltern, die keine Personennamen darstellen. Ferner stellt sich die Frage, warum die Kombination von lexikalischen und phonologischen Faktoren in diesem Fall nicht zu systematischer Endungslosigkeit (inkl. Markierung durch Apostroph) zu führen scheint (> 11.000 Fälle, 16,6%). Eine nähere Betrachtung der Daten zeigt allerdings, dass sich bei den overt markierten Formen eine Reihe von Fehlern eingeschlichen haben. So wird bei Wortformen mit Doppel-s am Wortende (überwiegend Fehlschreibungen) das finale -<s> oft fälschlich als Flexionselement eingestuft. Darunter finden sich hier viele Fälle, in denen ein offensichtliches Appellativum als Eigenname behandelt wird (920x Erkenntniss, 644x Kenntniss, 408x Maass, 160x Knauss, 152x Verständniss, 119x Riess, 49x Unkenntniss etc.). Der tatsächliche Anteil der Nullendungen dürfte also tatsächlich wesentlich höher liegen.
Eigennamen und Grad der Integration
Wie bereits in Abschnitt Standardsprachlich anerkannter Wegfall der Genitivendung erwähnt, vertritt Nübling (2012) die Hypothese, dass es einen Zusammenhang gibt zwischen der Geläufigkeit/Häufigkeit eines Namens und der Wahl der Genitivmarkierung. Dies prognostiziert u.a., dass Fluktuationen in der Häufigkeit des Namens einen Einfluss haben sollten auf die Distribution der Nullendung. Mit anderen Worten, wir erwarten, dass ein häufigerer Gebrauch eines Namens eine stärkere Integration in das Flexionssystem bewirken kann, die sich u.U. in einer häufigeren Verwendung der s-Endung manifestiert. Um diese Prognose zu testen, haben wir das Flexionsverhalten zweier geografischer Namen, Iran und Irak, zwischen 1985 und 2009 näher untersucht. Es ergibt sich das folgende Bild:
| Jahr | Iraks | Irak | Irans | Iran |
| 1985-1989 | 42 (48,8%) | 44 (51,2%) | 71 (62,3%) | 43 (37,7%) |
| 1990-1994 | 332 (56,4%) | 257 (43,6%) | 73 (75,3%) | 24 (24,7%) |
| 1995-1999 | 438 (60,3%) | 288 (39,7%) | 403 (79,6%) | 103 (20,4%) |
| 2000-2004 | 1682 (69,4%) | 742 (30,6%) | 386 (82,5%) | 82 (17,5%) |
| 2005-2009 | 819 (72,2%) | 316 (27,8%) | 1316 (80,8%) | 312 (19,2%) |
Tabelle 2: Verhältnis Nullendung vs. s-Endung bei zunehmender Token-Häufigkeit
In dieser Stichprobe scheint ein z.T. massiver Anstieg der Häufigkeit von (Genitivformen von) Iran und Irak mit einer stetigen Abnahme des Anteils von endungslosen Genitiven einherzugehen. Dies könnte als Hinweis darauf verstanden werden, dass zumindest bei geografischen Namen das Verhältnis von Nullendung und s-Endung tatsächlich von der Geläufigkeit des Ausdrucks abhängig ist. Eine inferenzstatistische Analyse der Zahlen in Tabelle 2 zeigt allerdings, dass das Gesamtbild tatsächlich weniger eindeutig ist, als der erste Eindruck vermuten lässt. Zwar liegt eine generelle Entwicklung vor, die in beiden Fällen dazu führt, dass die Nullendung an Boden verliert. Wie die folgende Tabelle und der Assoziationsplot zeigen, verhalten sich die beiden Lemmata aber nicht identisch. Bei der Iraks/Irak Alternation ist der entsprechende Effekt insgesamt stärker und führt schließlich zu einer signifikanten Abweichung (Betrag größer als 1,96) von den erwarteten Häufigkeiten zugunsten der overten Markierung. Für das Lemma Iran hingegen lässt sich lediglich konstatieren, dass ursprünglich eine signifikante Abweichung zugunsten der Nullendung vorgelegen hat, die sich nach und nach abschwächt. Für die einzelnen diachronen Schnitte kann allerdings keine statistisch signifikante Präferenz für die s-Endung festgestellt werden:
| Jahr | Iraks | Irak | Irans | Iran |
| 1985-1989 | -2,04 | 2,89 | -2,11 | 4,21 |
| 1990-1994 | -3,1 | 4,39 | -0,52 | 1,03 |
| 1995-1999 | -2,13 | 3,02 | -0,08 | 0,15 |
| 2000-2004 | 1,56 | -2,22 | 0,61 | -1,22 |
| 2005-2009 | 2,21 | -3,14 | 0,4 | -0,8 |
Tabelle 3: Verhältnis von Nullendung und s-Endung bei diachron zunehmender Token-Häufigkeit: Pearson Residuals
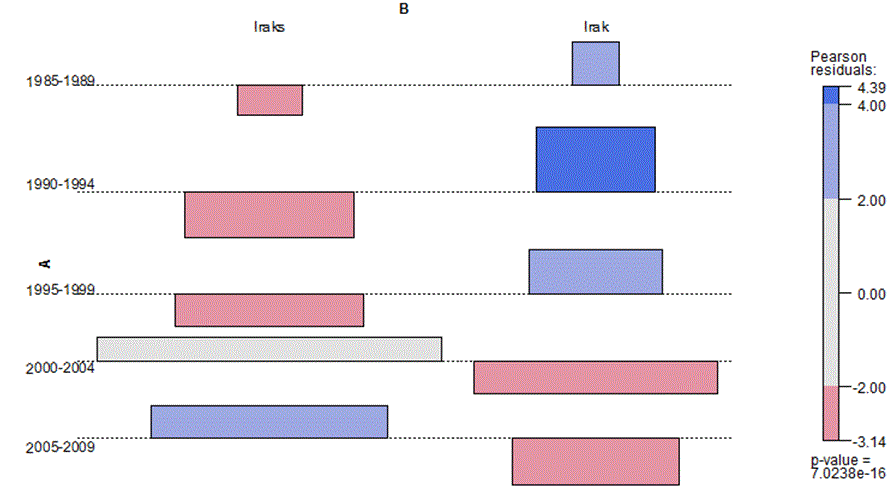
Abbildung 1: Assoziationsplot: Abweichungen von den erwarteten Häufigkeiten der Endungsvarianten bei Irak (diachrone Entwicklung)
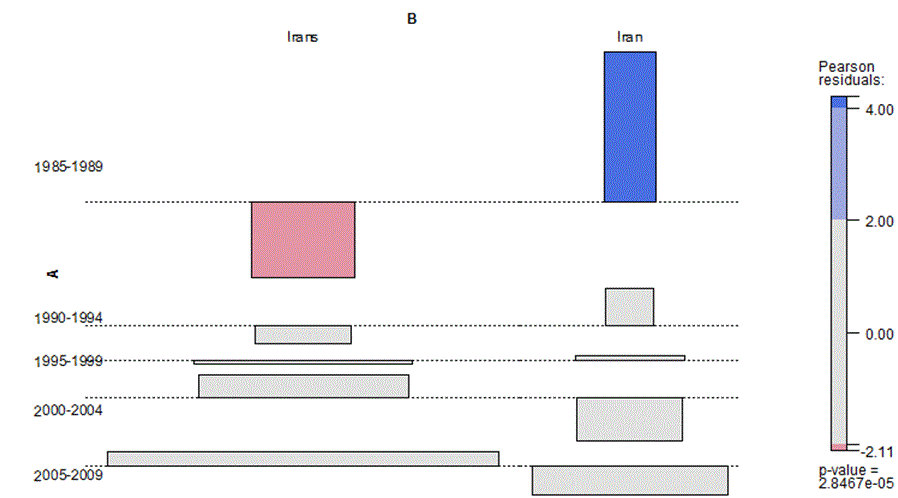
Abbildung 2: Assoziationsplot: Abweichungen von den erwarteten Häufigkeiten der Endungsvarianten bei Iran (diachrone Entwicklung)
Wir können also festhalten, dass bei näherer Betrachtung der Zusammenhang zwischen Geläufigkeit und Zunahme der s-Endung weniger eindeutig ausfällt, als die Zahlen in Tabelle Verhältnis Nullendung vs. s-Endung bei zunehmender Token-Häufigkeit zunächst suggerieren. Für eine zuverlässige Evaluierung der Hypothesen von Nübling müssen also offenbar noch umfangreichere Untersuchungen durchgeführt werden.

